
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- PHP #핵심정리
- C언어 #부록
- C언어 #핵심정리
- shell_script
- C++ 언어 # 핵심정리
- HTML #핵심정리
- C++ 언어 #핵심정리
- C++ 언어 # 핵심 정리
- MySQL #핵심정리
- C언어 # 부록
- Hacking #Baic
- Bandit
- C언어 # 핵심 정리
- Today
- Total
cCcode
C Language [핵심정리] - 27(수정) 본문
1. 구조체 포인터 사용하기
보통 구조체 멤버로 변수가 여러 개 들어있기 때문에 크기가 큰 편이에요. 그렇기에 일일이 구조체 변수를 선언해서 사용하는 건 비효율적이죠. 그래서 우린 포인터에 메모리를 할당해 사용할거에요.
다른 자료형들은 그 자체로 포인터를 선언할 수 있었죠? 마찬가지로 구조체 또한 포인터로 선언할 수 있습니다. 그리고 구조체 포인터는 malloc 함수를 사용해 동적메모리를 할당할 수 있어요.



일단 struct hobby * h1처럼 struct 키워드에 구조체 명을 사용해 구조체 포인터를 선언합니다. 그리고 malloc 함수로 메모리를 해당 구조체 크기만큼 메모리를 할당합니다. 여기서 구조체 멤버에 접근하기 위해선 일반적으로 사용하던 . 이 아닌 ->(화살표 연산자)를 사용해 구조체 포인터 멤버에 접근합니다. 그 후 마지막으로 free를 통해 할당한 메모리를 해제해주세요. 저도 가끔가다 해제하는 걸 잊을 때가 있습니다. 해제를 하지 않는다 해서 값이 크게 달라지는 건 아니거든요. 하지만 지금은 문제가 없는 '것'처럼 보일 뿐 나중에는 심각한 메모리 누수를 발생시킬 수 있기에 꼭 메모리를 해제 해줍시다!
+ 구조체 포인터에서 . 으로 멤버에 접근하는 방법
일반적으로는 ->(화살표 연산자)를 사용한다 말씀드렸죠? 그럼 화살표 연산자는 주소를 직접적으로 가리키는 연산자라 볼수 있겠죠? 그럼 저희가 그전에 배운 포인터의 역참조를 통해 값에 직접적으로 접근할 수 있지않을까요? 그럼 바로 확인하시죠.


저희가 예상한대로 역참조 후 .을 통해서 접근하면 화살표 연산자와 같은 효과를 낼 수 있습니다. 이제 "구조체 포인터는 멤버들이 포인터라는 뜻이 아니라 구조체를 사용하기 위해 선언한 구조체 변수가 포인터라는 의미"인건 모두 아시겠죠?
그럼 이제 struct 키워드가 아닌 typedef 로 정의한 구조체 별칭으로 포인터를 선언하고 메모리를 할당해볼게요.



여기서 주의해야 할 부분은 sizeof 연산자를 사용해 해당 구조체의 크기만큼 메모리를 할당할 때도 별칭으로 명시해줘야 한다는 부분입니다. 구조체 별칭으로 선언한 포인터 또한 ->(화살표 연산자)를 통해 멤버에 접근합니다.
+ 익명 구조체 또한 구조체 명을 생략하고 별칭만 사용하기 때문에 별칭을 사용한 동적할당과 문법이 동일합니다.
저희가 포인터를 처음 배울 때는 변수의 주소를 담은 후 역참조를 통해 그 값을 수정했었죠 기억나시나요? 이를 이용해서 저희는 구조체 포인터에 구조체 변수의 주소를 담을 수 있는데요 어떻게 사용하는 지는 다음 예제를 확인하시죠.

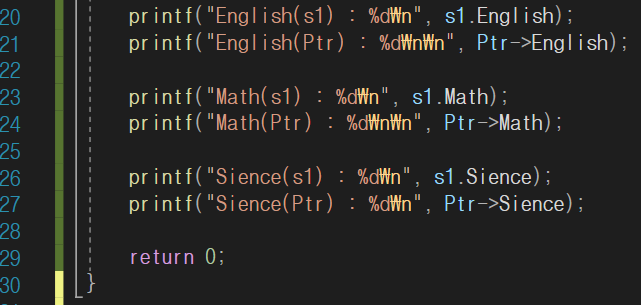

저 코드에서 주소연산자를 통해 변수의 주소를 포인터에 할당해서 즉, Ptr에 s1의 메모리 주소를 할당했으므로 Ptr의 멤버를 수정하면 결국 s1의 멤버 또한 바뀌게 됩니다.
2. 구조체 멤버 정렬하기
저희는 그전 비트 연산을 배우며 컴퓨터에 CPU가 메모리에 접근할 때 32bit에선 4byte 단위, 64bit CPU는 8byte 단위로 접근한다는 걸 공부했었죠. 거기서 조금 더 나아가자면 32bit CPU에 4byte 보다 작은 데이터로 접근할 경우 내부 시프트 연산으로 인해 효율이 떨어집니다. 그래서 C언어는 CPU가 메모리의 데이터에 효율적으로 접근할 수 있도록 구조체를 일정한 크기로 정렬(alignment)합니다.
구조체 정렬을 하기 전 구조체 크기를 알아야겠죠? 그래야 몇 byte 단위로 정렬을 할지 정할 수 있습니다.
구조체의 전체 크기는 일반적인 경우와 마찬가지로 sizeof 연산자를 통해 알아낼 수 있어요.



위 코드를 보면 전체 크기는 char(1byte)에 int(4byte)로 5byte가 나와야 할 거 같은 실제로는 8byte가 나왔습니다. 그 이유는 C언어에서 구조체를 정렬할 때는 가장 큰 자료형의 크기의 배수를 기준으로 정렬하기 때문입니다. 여기선 int 가 가장 크므로 4byte를 기준으로 정렬합니다.
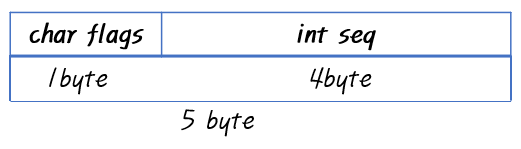

4byte로 정렬해서 flags와 seq가 모두 들어가는 최소 크기는 8byte가 됩니다. 여기서 1byte 크기의 char flags 뒤에는 4byte 공간을 맞추기 위해 남는 공간에 3byte가 더 들어갑니다. 이처럼 구조체를 정렬할 때 남는 공간을 채우는 걸 패딩(padding)이라고 합니다.
이제 offsetof 매크로를 사용해 구조체에서 멤버의 위치(offset)을 구해볼까요. (<stddef.h> 파일에 정의되어 있습니다.)


offsetof 매크로에 구조체와 멤버를 지정하면 구조체에서 해당 멤버의 상대위치가 반환되는데요. (첫 멤버의 상대위치는 0입니다.) 여기서 구조체가 4byte 단위로 정렬하기에 seq위치는 1이 아닌 4가 나옵니다.
+ 추가
솔직히 저도 좀 이해가 되지 않았거든요. 그래서 코드를 작성해보면서 알아본 결과를 한번 같이 살펴 보시죠.


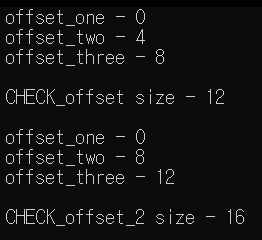
일단 첫 번째 구조체를 보면 int 자료형이 제일 크므로 4byte 배수를 기준으로 정렬하고 두 번째 구조체는 double 자료형 즉, 8byte를 기준으로 정렬합니다.
ex) 첫 번째 구조체 : 1(char) + 1(char) + 4(int) + 2(padding) = 8
두 번째 구조체 : 1(char) + 4(int) + 8(double) + 3(padding) = 16
여기까지는 괜찮죠? 이제부터 이해하기 힘든 상대위치에 대해 말해볼게요.
이를 통해서 저는 상대 위치라는 게 그 멤버가 시작하는 위치라는 걸 알았어요.
ex) 두번 째 구조체에서
첫번 째 멤버(double)는 말 그대로 0에서 시작합니다. 그리고 0 ~ 8까지 공간을 가지게 되죠. - [상대위치 0]
그럼 두 번째 멤버(int)는 당연히 8부터 시작합니다. 그리고 8 ~ 12까지의 공간을 가지게 되죠. - [상대위치 8]
그렇기 때문에 세 번째 멤버(char)는 시작위치 즉, 상대위치가 12입니다.
다만 제가 여러번의 시도를 한 끝에 한가지 사실을 발견했습니다. 바로 char 자료형의 멤버는 무슨 수를 기준으로 하던 항상 x ~ x + 4 라는 공간을 가지더라고요. 따라서 첫 번째 구조체 첫 번째 멤버(char)는 0에서 시작해 0 ~ 4까지의 공간을 가지므로 두 번째 멤버(int)의 상대 위치, 즉 시작 위치가 4 입니다. 다른 자료형 멤버들은 모두 자신의 자료형 고유의 크기를 가집니다. (그래서 우리가 생각하는 char은 1 이라는 공간을 가지니까 0 ~ 1까지의 공간을 가지고 두 번째 멤버인 int의 시작값은 1이 될거야 라는 가정은 무의미하게 된것이죠.)
어째서 char 멤버가 기준에 상관없이 항상 4라는 공간을 가지게 되는지는 알지못합니다. 이를 다루는 자료가 너무 없거든요. 나중에 더 찾아보고 알게된다면 다시 말씀드리겠습니다.
'C Language Basic' 카테고리의 다른 글
| C Language [핵심정리] - 29 (0) | 2021.06.15 |
|---|---|
| C Language [핵심정리] - 28 (0) | 2021.06.15 |
| [부록] 문자열 함수들을 이용한 간단한 프로그램(완성본) (0) | 2021.06.09 |
| C Language [핵심정리] - 25 (0) | 2021.06.08 |
| C Language [핵심정리] - 24 (0) | 2021.06.06 |



