
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- C++ 언어 # 핵심정리
- HTML #핵심정리
- C언어 # 부록
- C++ 언어 #핵심정리
- C언어 #핵심정리
- Bandit
- Hacking #Baic
- MySQL #핵심정리
- PHP #핵심정리
- C언어 #부록
- C언어 # 핵심 정리
- C++ 언어 # 핵심 정리
- shell_script
- Today
- Total
cCcode
C Language [핵심정리] - 43 본문
1. 파일 포인터 활용하기
지금까지 파일을 사용할 때는 파일 크기를 이미 알고 있었기에 버퍼 크기를 파일 크기보다 크게 작성하는 게 가능했습니다. 하지만 실제로 파일 크기를 가정하고 코드를 작성할 수는 없습니다.
그래서 해당 파일의 크기를 구하고 싶다면 fseek 나 ftell 함수를 사용하면 됩니다. (<stdio.h>파일에 선언되어 있습니다.)


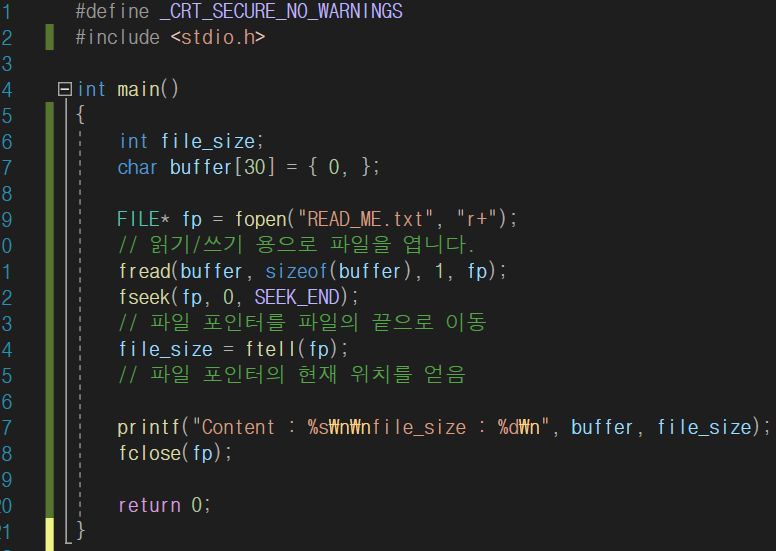

파일 크기를 구할 때도 파일 포인터가 필요합니다. 따라서 fopen 함수 파일모드 "r"로 열었습니다.
fseek 함수는 기준점에서 이동할 거리(크기)를 지정하여 파일 포인터를 이동시킵니다. 그 후 읽기/쓰기 함수를 사용한다면 그 파일 포인터가 이동된 위치부터 읽기/쓰기를 하게 됩니다. SEEK_END 외에도 fseek 함수에는 총 기준점 3개가 존재합니다.

간단히 말해 SEEK_SET은 파일의 처음, SEEK_END는 파일의 끝, SEEK_CUR는 파일 포인터의 현재 위치를 의미합니다.

예를 들어 fseek(fp, 0, SEEK_SET); 은 파일의 처음으로 이동합니다. 그런데 이동할 거리가 0이기 때문에 파일 포인터는 처음으로 이동하는 거나 다름없습니다. fseek(fp, 0 SEEK_END); 역시 마찬가지로 파일의 끝에서 0만큼 이동하므로 결국 파일 끝으로 이동합니다.
만약 현재 위치의 파일 포인터를 순방향으로 이동하고 싶다면 이동할 크기를 양수로 지정해주고, 역방향으로 이동하려면 음수를 지정하면 됩니다. 그리고 파일 포인터의 이동방향은 포인터 연산과 동일하기 때문에 순방향으로 이동시키면 파일 포인터의 위치값이 커진다라고 표현할 수 있습니다. 그리고 ftell 함수를 사용하면 파일의 현재위치(= 크기)를 얻을 수 있습니다.
(이 파일의 크기는 문자열의 개수(널문자를 제외한)와 동일합니다.)
+ 파일 포인터(file pointer)는 FILE 구조체의 포인터 또는 실제 파일의 읽기/쓰기 위치를 가리킨다고 하여 파일 포인터라고 부릅니다.
전까지는 파일 크기를 모른 상태에서 임시로 버퍼의 크기를 생성했습니다. 이 때 버퍼의 크기가 파일 크기 보다 작다면, 내용을 모두 읽을 수 없습니다. 다만, 모든 내용을 읽을 수 없을 뿐 내용을 아예 읽지 못하는 건 아닙니다. 이 문제를 해결하기 파일 크기를 구한 후 해당 크기만큼 버퍼를 생성하고 파일을 읽겠습니다.
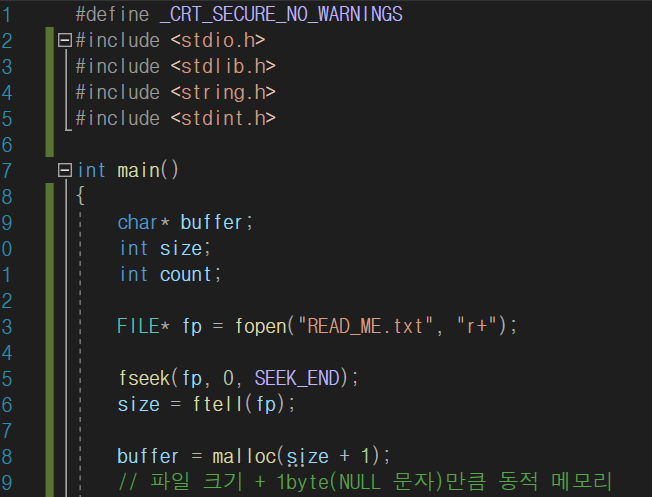

코드가 길어서 어려워 보일 수도 있지만, 이것만 기억하시면 됩니다.
1) 크기를 구할 때는 + 1을 해서 NULL문자가 들어갈 공간을 포함해야 합니다.
ftell 함수로 파일 포인터의 위치를 구하면 NULL문자를 제외한 위치가 나오기 때문입니다.
2) 할당한 메모리에 memset 함수로 초기화 합니다.
메모리를 NULL로 초기화 하지않으면, 그전에 다른 값이 들어있을 수 있기 때문에 문자열 이외의 값이 출력될 수 있습니다.
+ 파일의 앞부분은 파일의 내용을 읽기 위해서, 파일의 뒷부분은 파일의 크기를 구하기 위해서 위치를 이동시킨겁니다.
fseek 함수를 사용해 파일 포인터의 위치를 설정한 뒤 내용을 부분적으로 읽어보겠습니다.


파일을 부분적으로 읽어봤으니 이제 파일을 부분적으로 써보겠습니다.
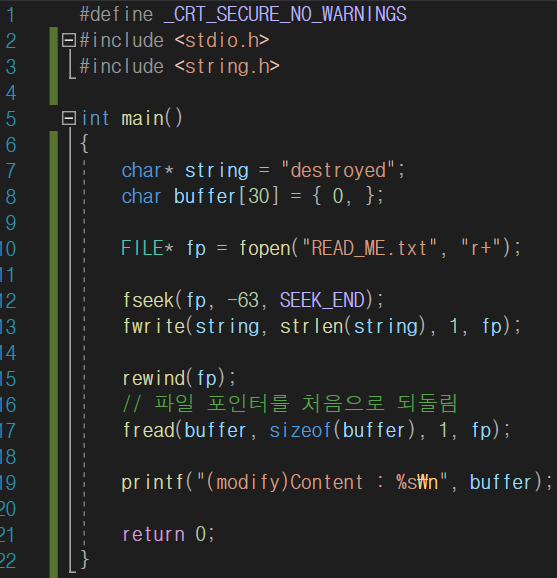

rewind 함수는 파일 위치 지시자를 처음 위치로 옮기는 함수입니다. (<stdio.h>파일에 정의되어 있습니다.)
만약 파일의 크기가 버퍼를 생성하기 힘들정도로 크다면 한 버퍼에 해당 파일의 내용을 담는 건 무리일겁니다. 하지만 파일이 끝인지 확인하는 feof 함수를 이용하면 제한된 버퍼로 파일 전체를 읽어볼 수 있습니다. (<stdio.h>파일에 정의되어 있습니다.)

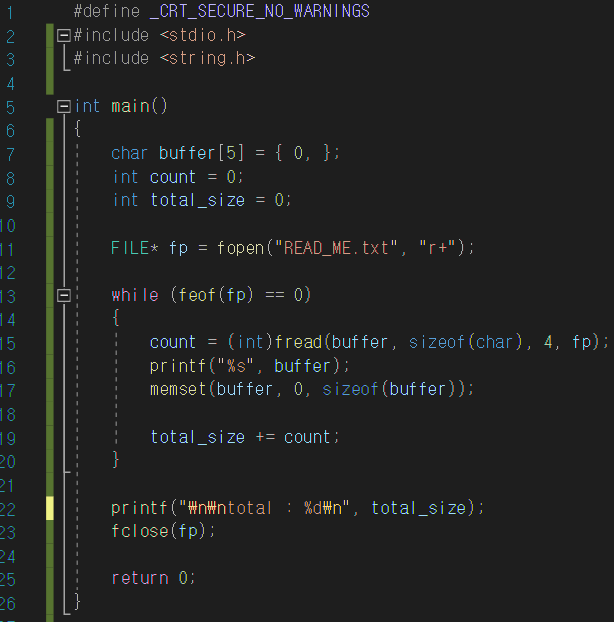

위에 버퍼의 크기가 5인 이유는 문자열 데이터(문자열 하나에 1byte)를 부분적 4byte 씩 나눠서 읽기 위해서 입니다. 따라서 더 크게 지정해도 상관없어요. 다만 읽을 때마다 널문자를 포함해야 하기 때문에 생각한 문자열의 크기에 1을 더해줘야 합니다. 그리고 while 문의 조건식은 feof 의 반환값을 이용해 파일 포인터가 끝날 때까지 반복합니다.
fread는 fread(버퍼, 읽기 크기, 읽기 횟수, 파일 포인터)이기 때문에 저는 4byte 만큼 순방향으로 이동할 계획으로 코드를 작성했기 때문에 sizeof(char) - 1byte 를 4번 반복하는 것 즉, 4byte 만큼 순방향 이동하도록 작성했습니다만 굳이 이런 식으로 작성할 필요는 없습니다. 다만, 읽기 크기 x 읽기 횟수 가 버퍼의 크기 - 1 만큼만 나오면 되요.
예를 들어 제가 버퍼를 10으로 (= 10씩 끊어서 문자열 데이터를 읽는다면) 잡는다면


fread 함수를 이와 같이 설정해줘야 합니다. 3 x 3 = 9 만큼 읽는 건데, 그 이유는 그전에 설명드린 것처럼 파일의 크기에는 널 문자가 포함되지 않기 때문입니다. 그리고 total_size 는 이렇게 나온 count(= 파일의 일부 크기)를 모두 더해 파일의 총 크기를 구하는 역할입니다.
파일이 클 경우 이런 식으로 코드를 작성하면 제한 된 버퍼로 파일의 크기를 구할 수 있고, 파일의 내용을 모두 확인할 수 있어요. + feof 함수는 파일 포인터의 위치가 끝이면 1, 아니면 0을 반환합니다. 그래서 EOF 와 혼동하는 경우가 생기는데, EOF는 함수에서 값을 읽을 수 없는 상태일 때 반환되기 때문에 feof와 EOF는 상관없어요.
2. 정렬하기
프로그래밍을 하다보면 마구잡이로 섞여있는 값들을 오름차순이나 내림차순으로 정렬해야하는 경우가 생깁니다.
오늘은 정렬 알고리즘 중 가장 간단한 거품 정렬(bubble sort)를 구현해보겠습니다.
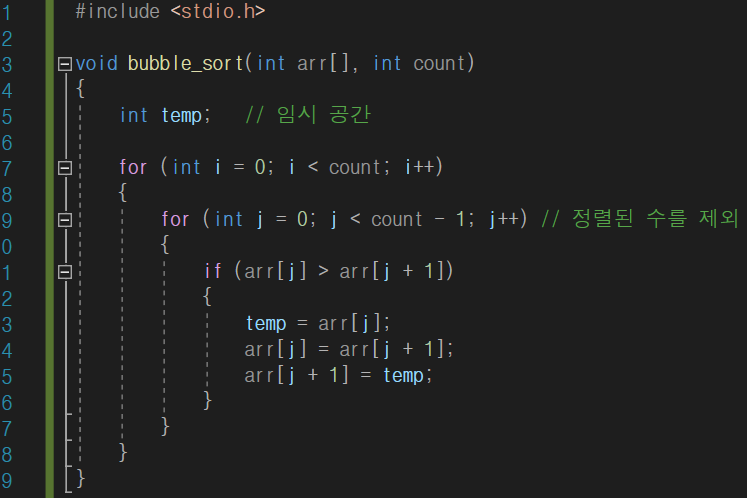

거품 정렬은
1) 처음부터 끝까지 모든 요소를 돌며, 비교한다. (단, 한번 정렬을 시도해 정렬이 된 값은 제외하고 다음 정렬을 실행한다.)
2) 현재의 값과 다음 값을 비교해 더 큰 값을 다음으로 보낸다 (오름차순)
라는 규칙만 알고 계시면 간단히 이해할 수 있습니다. 아,, 그리고 제가 주석을 잘못 작성했습니다.
bubble_sort 함수에서 두번째 for문에서 count - 1 값은 정렬된 수 제외가 아니라 인덱스를 벗어난 값과 비교하지 않기 위해서 입니다.
EX) 만약 count - 1 을 하지 않았다면
j = 4 일 때, 4번째 인덱스와 +1 을 한 5번째 인덱스를 비교하게 되는데요. 이때는 인덱스가 0부터 시작하기 때문에 0 1 2 3 4 이렇게 5개의 배열 요소를 가지는 겁니다. 따라서 방금 말한 것처럼 5번째 인덱스에 저장된 값은 존재하지 않는 것이죠 그러니까 다른 말로하면 배열의 마지막 요소와 배열 인덱스 범위를 벗어난 요소끼리 비교하게 되는 겁니다. 실제로 수정한 후 컴파일 해보면
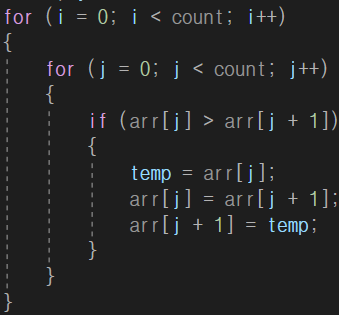
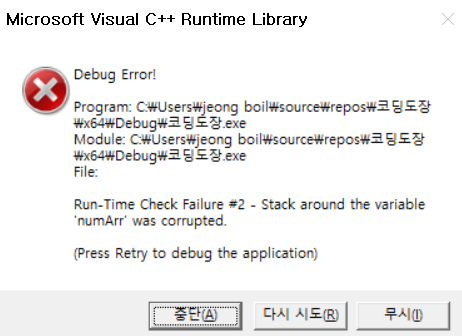
에러가 발생합니다.
거품 정렬을 일일히 구분하자면 다음과 같이 구분할 수 있습니다.

그런데 위에 있는 코드로 실행하면 이처럼 불필요한 반복이 생겨납니다. 이런 불필요한 반복을 줄이려면 count 를 두 번째 반복문이 끝날 때마다 1씩 빼주면 되요. 왜냐하면 두번째 반복문이 한번 끝난다는 의미는 가장 큰 숫자의 정렬이 끝난 다는 의미인데요. 그렇다면 - 1을 빼서 가장 마지막 인덱스에 위치하게 된 가장 큰 수를 제외해야 쓸데없는 반복을 줄일 수 있어요.
1) 수정하지 않은 원본 코드의 반복 횟수 총합
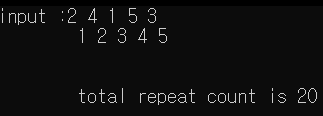
2) 수정(최적화)한 코드의 반복 횟수 총합 (두 번째 반복문이 끝날 때마다 count 를 1씩 빼는 경우)
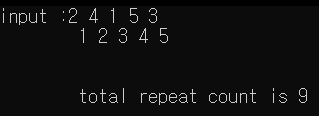
와오.. 한눈에 봐도 반복횟수가 줄어든게 보이시죠? 저도 차이가 이렇게 심할 줄은 몰랐네요.
+ 해당 정렬 방법이 버블 정렬이라 불린 이유는 정렬되는 모습이 마치 거품이 올라오는 것 같다하여 거품(bubble)정렬 이라고 합니다. 그리고 버블 정렬의 시간 복잡도는 O(n^2)를 가집니다. 이걸 Big O 표현법이라고 합니다.
Big O 표현법이란?
일단 알고리즘의 시간 복잡도를 표현할 때는 일반적으로 생각하는 초, 분, 시 와 같은 단위로 표현하지 않습니다. 왜냐하면 개인 컴퓨터마다 실제로 작동되는 시간이 다르기 때문에 알고리즘의 시간복잡도는 수행하는 절차를 단위로 표현합니다.
예를 들어 데이터들을 하나씩 검사하는 알고리즘이 존재한다고 생각합시다. 그 경우에는 가지고 있는 데이터를 모두 확인하겠죠. 만약 7개의 데이터를 가지고 있다면 7번의 절차가 발생하는겁니다. 이 때 데이터의 개수가 정해지지 않았고 입력값으로 데이터의 개수를 받는 다면 이때 입력값을 N(미지수)으로 잡을 때 N개의 절차가 필요하게 됩니다. 따라서 해당 알고리즘을 빅오 표현법으로 표현한다면 O(N) 이라는 시간복잡도를 가지게 됩니다. 그래프로 나타내면 다음과 같습니다.
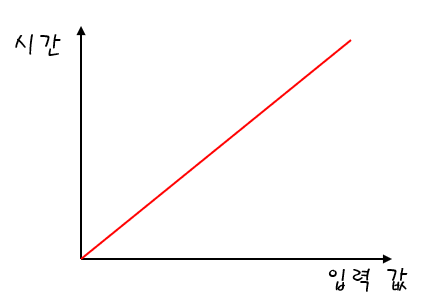
입력값이 늘어날 수록 시간 또한 동시에 증가한다는 의미입니다.
int arr[3] = { 1, 2, 3 };
printf("%d\n, arr[0]);
// 한 개의 요소 출력이 경우에는 해당 배열이 얼마나 큰가에 대해 상관없이 한개의 절차(출력하는 부분)만을 거칩니다. 따라서 빅오 표현법으로는 O(1)이 되는것이죠.
int arr[3] = { 1, 2, 3 };
printf("%d\n, arr[0]);
printf("%d\n, arr[1]);
// 두 개의 요소 출력그럼 이 경우에는 두 개의 절차를 거치니까 O(2)인걸까요? 아쉽게도 틀렸습니다. 이 경우에도 O(1)이 되요. 왜냐하면 빅 오 표현법은 세세한 부분은 표현하지 않거든요. (= 상수를 신경쓰지 않습니다.) 그래프로 그리면 다음과 같습니다.
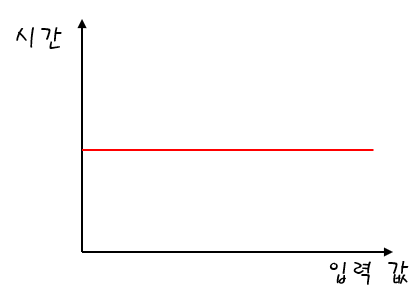
입력값과 상관없이 시간이 일정하다는 걸 의미합니다. 이 알고리즘은 상수 시간 알고리즘(Constant Time Algorithm) 이라고 불립니다.
다른 시간 복잡도로는 2차 시간(Quadratic Time)이 있습니다. 이 경우에는 중첩 반복이 있을 때 사용하는데
int arr[3][3] = {0,};
for (int i = 0; i < 3; i++)
{
for(int j = 0; j < 3; j++)
{
printf("%d ", arr[i][j]);
}
printf("\n");
}이 경우 시간 복잡도는 O(N^2)가 되는 것이죠. ex) 입력값이 10개라면 100개의 절차를 수행해야 하겠죠. 그래프로 그리면 다음과 같은데, O(N) 과 비교하면 당연히 O(N)이 더 효율적입니다.

'C Language Basic' 카테고리의 다른 글
| C Language [핵심정리] - 45 (0) | 2021.08.01 |
|---|---|
| C Language [핵심정리] - 44 (0) | 2021.07.29 |
| [부록] 막대 그래프(완성본), 체스 말 움직이는 모션(완성본) (0) | 2021.07.24 |
| C Language [핵심정리] - 41 (0) | 2021.07.22 |
| C Language [핵심정리] - 40 (0) | 2021.07.20 |



