C++ Language [핵심정리] - 3
1. struct(구조체) 와 class(클래스)
Class 는 기본적으로 자료 저장(변수의 역할) + 자료 처리(함수의 역할)을 겸하고 있습니다. 즉, class 는 변수와 함수를 묶어놓은 형태라고 할 수 있겠네요. 그리고 이를 하나의 틀로 보면 하나의 자료형으로 생각해도 됩니다.
이처럼 저희가 특정한 틀(자료형)을 사용해서 만든 변수를 저희는 객체(오브젝트)라고 부릅니다. 그래서 객체라는 단어가 나온다면 변수 또는 메모리상의 공간으로 대체 해석해도 됩니다.
일단 구조체를 사용해보겠습니다.

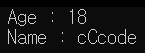
이 경우 다음과 같은 경고가 하나 뜨게 됩니다.

Private_Information 이라는 구조체의 age 변수가 초기화 되지 않았다는 경고입니다. 사실 경고일뿐이므로 무시해도 되지만, 경고를 해결하는 습관을 들이기 위해 해결해보겠습니다. 이 경고는 말그대로 멤버를 초기화 하면 해결되는데 이 초기화 방법이 총 3개가 있습니다. (사소한 방법 포함).
1) 구조체 변수 선언과 동시에 초기화


여기서 중요한 점 string을 초기화할 때는 흔히들 문자열이라 NULL 을 생각하시는 데 NULL 이 아닌 " " 문자 입니다.


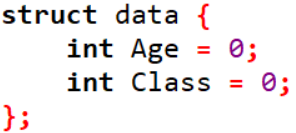
2) 구조체에서 초기화 하는 경우

이 경우 C++ 에서만 사용할 수 있습니다.

3) memset 함수 사용


이 때 제가 주석으로도 표시했지만 설정할 값으로는 int형만 사용할 수 있기 때문에 string 형의 변수를 초기화할 수 는 없습니다. 사실 string형 같은 경우에는 초기화를 해주지 않아도 되요.
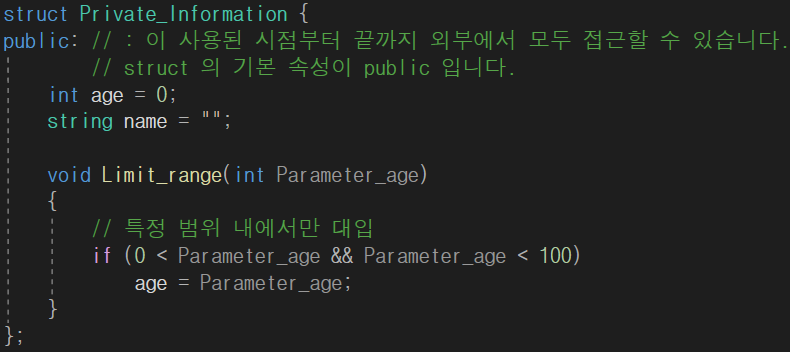
구조체의 멤버 중 제한 범위를 두어서 값이 예상범위 내에 있도록 만들려면 구조체 안에 함수를 사용해서 특정 분기에서만 해당 값이 대입되게 만들면 됩니다.




이 경우에는 함수를 호출하고 매개변수로 준 값을 변수에 대입했습니다. 하지만 만약 함수가 아닌 변수에 바로 값을 대입할 경우 범위를 제한할 수 없는 그러니까 원하지 않는 결과가 나올 수 있습니다. 그래서 C++ 에선 접근 제어 지시자를 제공합니다.


이번에는 private 와 public 만 사용하겠습니다.

private는 직역하면 개인의, 사적인 그러니까, 구조체에서만 해당 부분이 사용가능합니다. 그래서 private 접근 제어 지시자를 사용하고 구조체의 멤버(변수나 함수)를 사용한 부분을 확인하면

이처럼 해당 부분을 엑세스(사용)할 수 없다는 에러가 뜨게 됩니다.
그럼 이 private 라는 지시자는 대체 언제 사용하는가? 라는 의문이 들 수 있습니다. 단도직입적으로 말하면 해당 지시자는 변수의 선언부 같은 내부적인 속성들을 보호할 때 사용합니다.
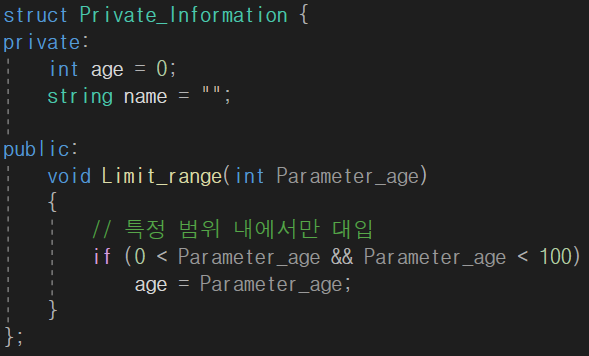
그리고 외부에서도 구조체 내의 속성을 사용하게 하고 싶다면 public 지시자를 사용하면 됩니다.

이렇게 보면 처음 구조체를 썼을 때와 달라진게 없죠..? 네 그렇습니다. 구조체는 따로 명시하지 않아도 public 속성을 띄게 됩니다. 그래서 private 를 사용하려면 따로 명시를 해줘야 하죠.
이처럼 private 그리고 public 지시자를 공부했는데, 일반적으로 두 지시자는 다음과 같이 사용합니다.
이처럼 내부적인 속성들은 보호하면서 외부 사용자들에게 속성들에 접근할 수 있는 인터페이스를 만들어주는 걸 캡슐화(encapsulation)라고 합니다.
+ 캡슐화의 개념
캡슐화는 객체지향 프로그래밍에서 다음과 같은 2가지 측면이 있습니다.
1) 객체의 속성(data fields)과 행위(methods)를 하나로 묶는다.
2) 실제 구현 내용의 일부를 외부에 감추어 은닉한다.
- 출처 위키백과 -
* 예시
#include <iostream>
#include <string>
using namespace std;
struct Private_Information {
private:
int age = 0;
string name = "";
public:
void Limit_range(int Parameter_age)
{
// 특정 범위 내에서만 대입
if (0 < Parameter_age && Parameter_age < 100)
age = Parameter_age;
// 외부에서는 속성에 접근할 수 없기 때문에 구조체 함수에서
cout << " Age is " << age << endl;
}
void Limit_String_Lenth(string str)
{
int cnt = str.length();
if (cnt < 10)
name = str;
// 따로 출력문을 작성해줘야 합니다.
cout << " Name is " << name << endl;
}
};
int main()
{
// 구조체 변수 선언
Private_Information P1;
P1.Limit_range(101);
P1.Limit_String_Lenth("cCcode");
return 0;
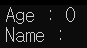
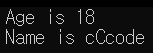
}결과 - 1 (조건을 만족한 경우)

결과 - 2 (조건을 둘다 만족하지 못한 경우)

이왕 string 클래스를 사용했으니, 그전에 못했던 설명을 덧붙이자면 string 클래스는 말그대로 string(문자열)을 다루는 클래스로 C언어에서의 char 포인터나 배열과 달리 널문자가 없습니다. 그리고 std::string 에서는 문자열을 다루는 수많은 함수들이 존재합니다. 그중에서 일부만 정리하면 다음과 같습니다.
string str;
1) str.operator[index]
C++ string은 일반 배열처럼 대괄호를 이용해 string 인자에 접근할 수 있습니다. (+ 인덱스는 당연히 0 부터 시작합니다.)
ex) str[1]


2) str.size();
string 의 크기를 반환합니다.
ex) str.size();
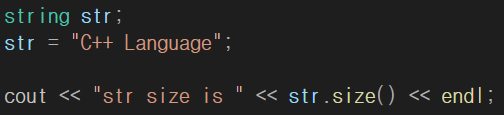

문자 하나에 1byte 따라서 C(1)+(2)+(3) (4) L(5)a(6)n(7)g(8)u(9)a(10)g(11)e(12)
이렇게 총 12byte 입니다.
3) str.length();
string의 길이를 반환합니다. 사실 문자의 크기가 1byte 라서 크기나 길이의 값은 동일합니다.
ex) str.length();

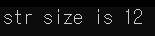
그래서 본론으로 돌아와 class 와 struct 의 차이점은 바로 struct 는 private 가 없으면 default 값이 public 이 되고 class는 public 이 없다면 default 값이 private 가 됩니다. 그게 차이점이겠네요.
2. this 포인터
흔히들 this 포인터를 객체 스스로를 가리키는 포인터라고 합니다.



분명히 다른 객체인데, this 포인터는 어떻게 구분하는걸까요?
this 포인터는 자신이 소속되어있는 객체의 주소를 가져오기 때문에 각 개체를 구분할 수 있는 겁니다. 여기서 코드만 봤을 때는 구조체 처럼 각 개체에 함수가 따로 존재한다고 생각할 수 있지만 곰곰히 생각해보면 사실 각 개체를 사용할 때마다 함수를 만드는게 얼마나 비효율적인지 깨닫게 될겁니다. 그래서 C++ 에서는 함수가 객체마다 존재하는 게 아니라 객체 외부에 존재하면서 불러오는 겁니다.

매개변수를 사용하면 이전과 동일하게 작동하도록 구현할 수 있습니다.




제가 처음 this 포인터를 봤을 때 일단 객체의 주소가 전달되어야 어떻게든 할텐데, 객체의 주소가 어떻게 전달되는지 이해가 되지않았거든요. 왜냐하면 보시다시피 함수의 전달값에는 공백 밖에 없잖아요. 제가 찾아본 결과 보이지 않는 매개변수가 존재한다고 합니다. 그만큼 유용하기 때문에 보이지 않는 매개변수 형태로 구조체와 클래스에 모두 존재한다고 해요.
3. 생성자와 소멸자
생성자 : 객체가 생성될 때 자동으로 호출되는 함수
소멸자 : 객체가 소멸될 때 자동으로 호출되는 함수
C++ 에서는 생성자(Constructor)를 이용해 객체를 생성함과 동시에 멤버 변수를 초기화할 수 있습니다. 생성자는 특별한 메소드로 클래스 명과 동일한 명으로 구현됩니다.
(메소드(Method)는 사전적의미로 방법과 수단이며, C++에서는 클래스의 멤버 함수들을 메소드라고 합니다.)
특징으로는 [1) 반환값이 없다. 2) 여러번 정의될 수 있다] 가 있습니다.
C++ 에서 별도로 생성자를 구현(클래스 명과 동일한 명으로 함수형태로)하지 않으면 기본 생성자(Default Constructor)가 사용됩니다. 기본 생성자는 매개변수를 가지지 않으며, 멤버 변수는 0 또는 NULL 로 초기화 됩니다.
C++ 에서 소멸자(Destructor)는 객체의 수명이 끝났을 때 객체를 제거하기 위해 사용되며, 객체의 수명이 끝났을 때 컴파일러가 호출합니다. 소멸자는 생성자와 동일하게 작성하되 앞에 ~(물결 표시)를 사용합니다.
일단 아셔야 할게 C++에서는 클래스의 변수를 정의하는 것을

클래스의 인스턴스화(instantiaing)라고 부릅니다. 변수 자체를 클래스의 인스턴스(instance)라고 하기 때문이죠. 또한 클래스 타입의 변수는 객체(object)라고도 불립니다.
본론으로 돌아와서 생성자와 소멸자를 사용해보겠습니다.



여기서 주의깊게 봐야할 부분은 22번째 줄 클래스 변수 선언하는 부분입니다. 프로그램의 흐름을 천천히 따라가자면
1) main 함수 호출 (+ 출력문 출력)
2) Test_Local_Object 함수 호출 (+ 출력문 출력)
3) 클래스 변수 선언 (= 생성자 호출, 출력문 출력)
4) Test_Local_Object 함수 출력문 출력 (+ 함수가 사라지며, 변수 또한 같이 사라져서 소멸자 호출, 출력문 출력)
5) main 함수 출력문 출력 (+ main 함수 종료)
이런 식으로 프로그램이 진행됩니다.


이처럼 아무것도 있지않은 클래스(= 기본 생성자)를 기준으로 클래스 변수를 만든 후 확인하면 (오직 클래스 변수의 클래스만 수정했습니다.)

그전에 존재했던 생성자와 소멸자 문구가 사라졌습니다. 우리는 이를 통해 클래스 변수의 생성자와 소멸자는 해당 클래스 내에서 지정해야 한다는 사실을 다시 한번 확인할 수 있었습니다.
* 생성자의 오버로드
#include <iostream>
using namespace std;
class Data {
public:
Data() { // 생성자 - 멤버 변수 초기화
age = 0;
Class_number = 0;
score = 0;
}
// 생성자 역시 함수이므로 오버 로드가 가능합니다.
Data(int age_, int Class_number_ , int score_)
{
age = age_;
Class_number = Class_number_;
score = score_;
}
void Factor_Check()
{
cout << "나이 : " << age << endl;
cout << "반 번호 : " << Class_number << endl;
cout << "점수 : " << score << endl;
}
private :
int age;
int Class_number;
int score;
};
int main()
{
Data d1;
d1.Factor_Check();
cout << endl;
Data d2(18, 19, 60);
d2.Factor_Check();
return 0;
}
생성자 역시 함수의 일종이므로 오버로드가 가능합니다. 이 역시 매개변수로 구분할 수 있죠.